A pesquisadora Monica Stephens, da Universidade de Humboldt State, utilizou tweets georreferenciados para determinar o local de origem de discursos de ódio nos Estados Unidos. Os dados – mais de 150 mil tweets – foram recolhidos entre Junho de 2012 e Abril de 2013. Após uma varredura feita por um algoritmo em busca de palavras-chave, os tweets foram avaliados pelos alunos de Stephens, que os classificaram. Os considerados negativos aparecem no mapa de calor.
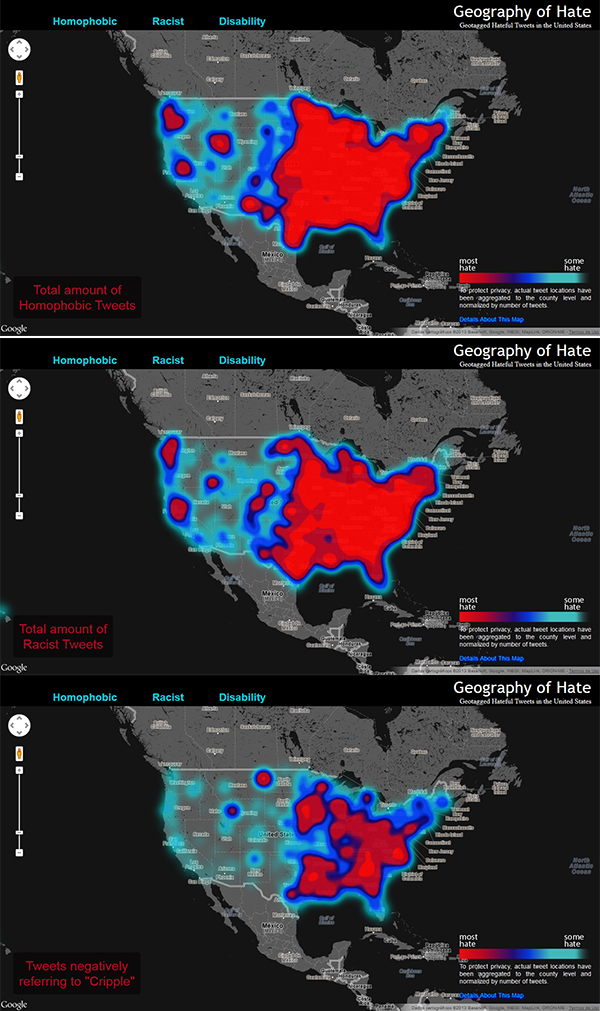
Típico caso de mau uso da estatística. A maior parte da informação exibida nos mapas esta associada a ouras variáveis como densidade populacional do país ou densidade de acessos à internet. Quando não se leva em conta a dependência entre variáveis surgem casos como este.
A costa leste é mais populosa e consequentemente possui um maior número de pessoas preconceituosas ou a costa leste simplesmente possui mais preconceituosos? Qual é a informação que interessa e quais são as conclusões que tiramos desses mapas?
Mas eles tentaram relativizar os dados, Ernesto. No sobre eles explicam:
‘To produce the map all tweets containing each ‘hate word’ were aggregated to the county level and normalized by the total twitter traffic in each county. Counties were reduced to their centroids and assigned a weight derived from this normalization process.’
Não são valores absolutos. E se vc aproximar ao máximo o mapa vc repara que os pontos de ‘mais ódio’ são bem dispersos (leste-oeste, norte-sul). A informação que vc tira do mapa depende de como vc lê o mapa, não?
A legenda “total amount” e a suavização dos dados a medida que afastamos o zoom, ao meu ver, dão um aspecto tendencioso à análise.
Realmente, o mapa faz mais sentido quando mudamos a escala de observação, mas o fato do tamanho das manchas ser proporcional à intensidade da variável prejudica a interpretação. Mapas em que o nível de agregação não fica evidente (condado, cidade, estado, …) dão margem a diferentes interpretações dependendo da escala observada.